Dữ liệu chúng ta thu thập có hình thù như thế nào ?
Ví dụ chúng ta có một tập dữ liệu các địa điểm trên thế giới
(Tokyo, Japan),
(Paris, France),
(Hanoi, Vietnam)Tập dữ liệu của chúng ta thu thập được dù nhiều đến đâu cũng luôn là không gian con có chiều thấp hơn chiều dữ liệu trong thực tế (input trong thực tế), tức là những địa điểm chúng ta có không đủ trên toàn thế giới. Có thể xem thêm hình dưới đây để dễ hình dung

Chúng ta có thể thấy với cách thông thường, không có cách nào để biểu diễn các thàn phố với ít hơn 3 điểm trong tọa độ x, y, z. Nhưng khoan, tất cả dữ liệu chúng ta thu thập trong thực tế không phải ngẫu nhiên, chúng đều tuân theo một cấu trúc cụ thể nào đó. Ví dụ tập dữ liệu của chúng ta tuân theo cấu trúc như sau

Việc các điểm dữ liệu đều tuân theo cấu trúc giúp chúng ta không cần toàn bộ các điểm dữ liệu trong không gian đó. Trường hợp này có thể chuyển về không gian hình cầu này, chúng ta có thể biểu diễn các điểm dữ liệu theo một chiều thấp hơn mà không làm mất mát thông tin
x = r.cos(θ).cos(ϕ)
y = r.cos(θ).sin(ϕ)
z = r.sin(θ)Trong đó:
- r là bán kính hình cầu.
- θ là vĩ độ (góc giữa bán kính nối điểm trên hình cầu với trục xOy).
- ϕ là kinh độ (góc giữa đường chiếu điểm lên mặt phẳng xOy với trục Ox).
Vậy là chúng ta đã thực hiện nén thành công một tập dữ liệu vào một chiều thấp hơn rồi, và đây chính là ý tưởng khởi nguôn cho kiến trúc AE ra đời.
AE (Autoencoders)
Là mạng ANN có khả năng học hiệu quả các embedding (biểu diễn của dữ liệu đầu vào trong một miền không gian xác định) mà không cần nhãn. Từ embedding này chúng ta có thể làm rất nhiều thứ ví dụ như bài toán phân loại, auto tagging,… hoặc có thể tái tạo lại output gần giống với input đầu vào, đây là một yếu tố rất quan trọng vì nó sẽ tiếp tục được sử dụng về sau trong các kiến trúc sinh ảnh hiện đại. Cụ thể hơn thì mọi người có thể hình dung như ảnh bên dưới:

Để làm được điều đó, kiến trúc AE được xây dựng như sau:
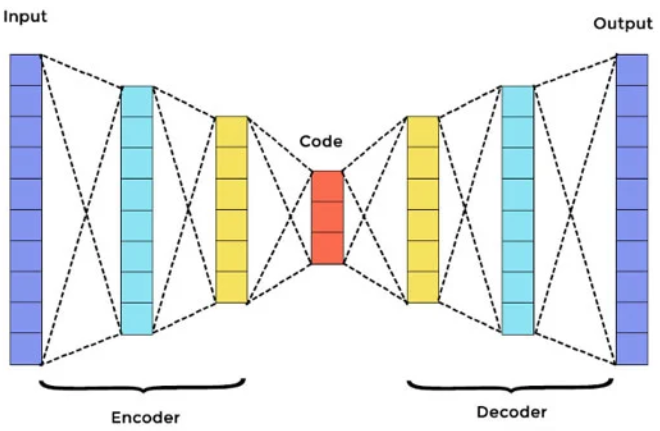
Trong đó mạng sẽ gồm 2 phần chính
- Encoder: Nén chiều data input thành chiều thấp hơn là embedding
- Decoder: Giải mã embedding thành ouput giống image origin nhất có thể.
Môt số lưu ý khi xây dưng mạng AE
(1) embedding càng nhỏ, càng sáng tạo vì mô hình sẽ chỉ chứa các thông tin quan trọng hơn để hiển thị.
(2) embedding nhỏ quá, lưu được quá ít thông tin, dẫn tới decode không ra. Rốt cuộc thì, cái gì Balance cũng mới tốt
Encoder
Đây chính là quá trình nén dữ liệu giống như ở phần 1 chúng ta đã nhắc tới, nén từ input thành embedding có chiều nhỏ hơn. Nhưng cần phải xem xét kỹ hơn lý thuyết này một chút, nếu embedding bằng đúng chiều nén nhỏ nhất của tập dữ liệu ( là chiều nhỏ nhất mà dữ liệu còn giữ được cấu trúc của mình). Thì mạng AE sẽ có xu hướng học sự ánh xạ 1:1 giữa ảnh đầu vào và ảnh đầu ra

Điều này là tuyệt vời khi nó đứng trong kiến trúc của Stable Diffusion và đặc điểm này làm nó trở nên quan trọng. Nhưng trước khi Stable Diffusion ra đời, người ta kỳ vọng nó có thể là một mô hình sinh ảnh tốt, do vậy họ lần lượt đề xuất các ý tưởng như sau:
- Ý tưởng 1: giảm chiều của embedding xuống nhỏ hơn nữa gây ra infomation loss => Điều này khiến ảnh đầu ra luôn giữ sự khác biệt so với ảnh đầu vào. Nhưng chiều đúng của embedding là bao nhiêu còn không biết, thì việc giảm xuống nhỏ hơn là một ngưỡng không xác định và nó có thể phá hủy kiến trúc của mô hình, gây ra sự biến dạng lớn trong ảnh đầu ra. => 💔
- Ý tưởng 2: Lúc này các nhà nghiên cứu là nghĩ ra một cách khác, thêm noise ngẫu nhiên vào ảnh đầu vào (giống ảnh minh họa dưới ) và bắt AE phải học được thêm cả cách giải mã noise nhiễu đó, điều này giúp vẫn giữ được sự ổn định của ảnh tạo ra và khả năng sáng tạo được bổ xung nhờ có noise ngẫu nhiên => ❤️

Decoder
Đây là quá trình biến embedding trở lại ảnh image origin. Đây là việc làm có gắng giải nén chiều thấp hơn thành chiều nhỏ hơn, ví dụ bạn có một tấm ảnh 2D và cố hình dung ra dạng 3D của nó như ảnh dươi vậy

Quá trình học
Quá trình tái tạo của AE tạo ra một sự khác biệt giữa input ( ví dụ là image origin ) và output ( ví dụ là image reconstructed )
image_reconstructed = Decoder(Encoder(image_origin + noise)) - image_origin
reconstruction_error = image_reconstructed - image_originBằng cách so sánh giữa output và chính input, mô hình tự điều chỉnh để giảm reconstruction_error này xuống thấp nhất, điều này giúp phần Encoder và Decoder phải phối hợp với nhau thông qua embedding để ít mất mát thông tin nhất => embedding luôn được điều chỉnh theo hướng đúng đắn nhất
Nhưng AE vẫn còn vấn đề
Thứ nhất, các embeding có mối liên hệ gần gũi (gần giống nhau) nhưng lại có distance khá xa nhau trong không gian latent, ví dụ cùng là bông hoa hồng, nhưng chụp bông hoa đó từ góc khác lại cho ra embedding ở một vị trí xa tít tắp 💢
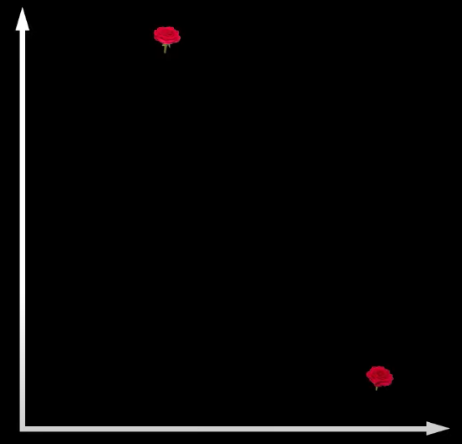
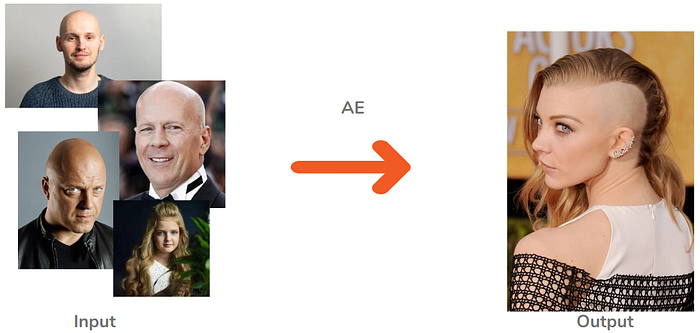
Thứ 2: Mất tính đầy đủ, chính vì không sắp xếp được vị trí của các embedding trong latent chính xác, cộng thêm việc bị bias theo tập dữ liệu đầu vào. Dẫn tới ảnh tạo ra chứa các thành phần không make sence với nhau một chút nào đứng cạnh nhau trong một bức ảnh, ví dụ ảnh dưới dữ liệu đầu vào có nhiều người bị hói thì ảnh đầu ra xác xuất sẽ có phần bị hói khá cao
VAE
Từ nhược điểm trên của AE, chúng ta cần một chiều latent tốt hơn để điều chỉnh phân bố của các đặc trưng hợp lý hơn và VAE ra đời để giúp chúng ta làm điều đó.
Thay vì mã hóa đầu vào là một embedding khiến các input giống như một điểm dữ liệu riêng biệt, ta chuyển không gian latent về dạng xác xuất phân phối chuẩn.

Luồng hoạt động của VAE sẽ thay đổi 2 phần so với AE như sau:
- Latent Distribution: Tạo ra một phân phối Gaussian với các tham số đã học μ và σ.
- Sampling z ∼ p(z ∣ x): Lấy mẫu từ phân phối Gaussian này để có được một biểu diễn không gian mã hóa z (embedding). Tức là vẫn sẽ đưa về dạng embedding nhưng đã được bao hàm cấu trúc của phân phối chuẩn trong đó.
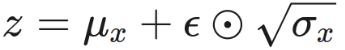
Việc không gian latent là một phân phối chuẩn giúp áp đặt một cấu trúc rõ ràng lên dữ liệu, tạo ra 2 lợi ích:
- Tạo ra một điểm neo cho embedding z, đây là sẽ điểm hút μ và σ dao động chứ không phải các embedding tự kéo nhau như AE
- Sự thay đổi μ và σ tạo nên sự khác biệt z khá lớn, do vậy sẽ khiến VAE tập chung điều chỉnh encoder để có z tốt trước rồi mới điều chỉnh phần decoder để overfit với z đó.
=> Những điểm này giúp dữ liệu phân bố theo một quy luật cụ thể chứ không ngẫu nhiên như AE. Các điểm dữ liệu mới trong tương lai sẽ có mối liên hệ nhất định với các điểm dữ liệu hiện tại => tạo ra các bức ảnh có ý nghĩa.
Ứng dụng
AE rất dễ dàng nắm bắt được cấu trúc của dữ liệu và khó học các điểm outliner do vậy có thể dùng để
- Feature Extractor: Trích xuất embedding chứa thông tin quan trọng, đặc trưng của tập dữ liệu, dễ huấn luyện hơn cho các task khác nhau ( phân loại, phân cụm,…)
- Anomaly Detection mà không cần nhãn: Chỉ cần sử dụng reconstruction_error, bạn sẽ biết được những điểm dữ liệu nào khác thường so với những điểm dữ liệu còn lại
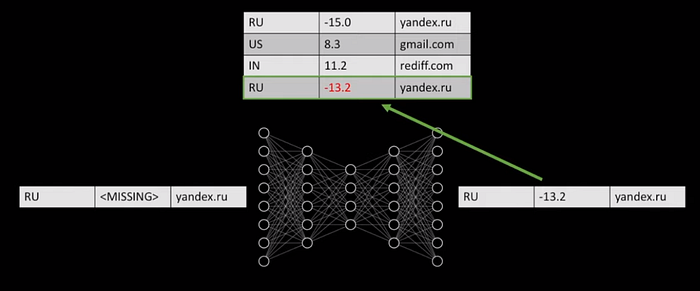
3. Missing Value Imputation: Dự đoán các giá trị bị khuyết
Qua bài viết này hy vọng mọi người sẽ hiểu hơn về các mà VAE hay AE đang hoạt động và được ứng dụng như thế nào trong thực tế, trong tương lai mình sẽ tiếp tục viết thêm các bài viết mới về VQ-VAE,… mọi người cùng đón xem nhé !
